LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Materials
Abstract
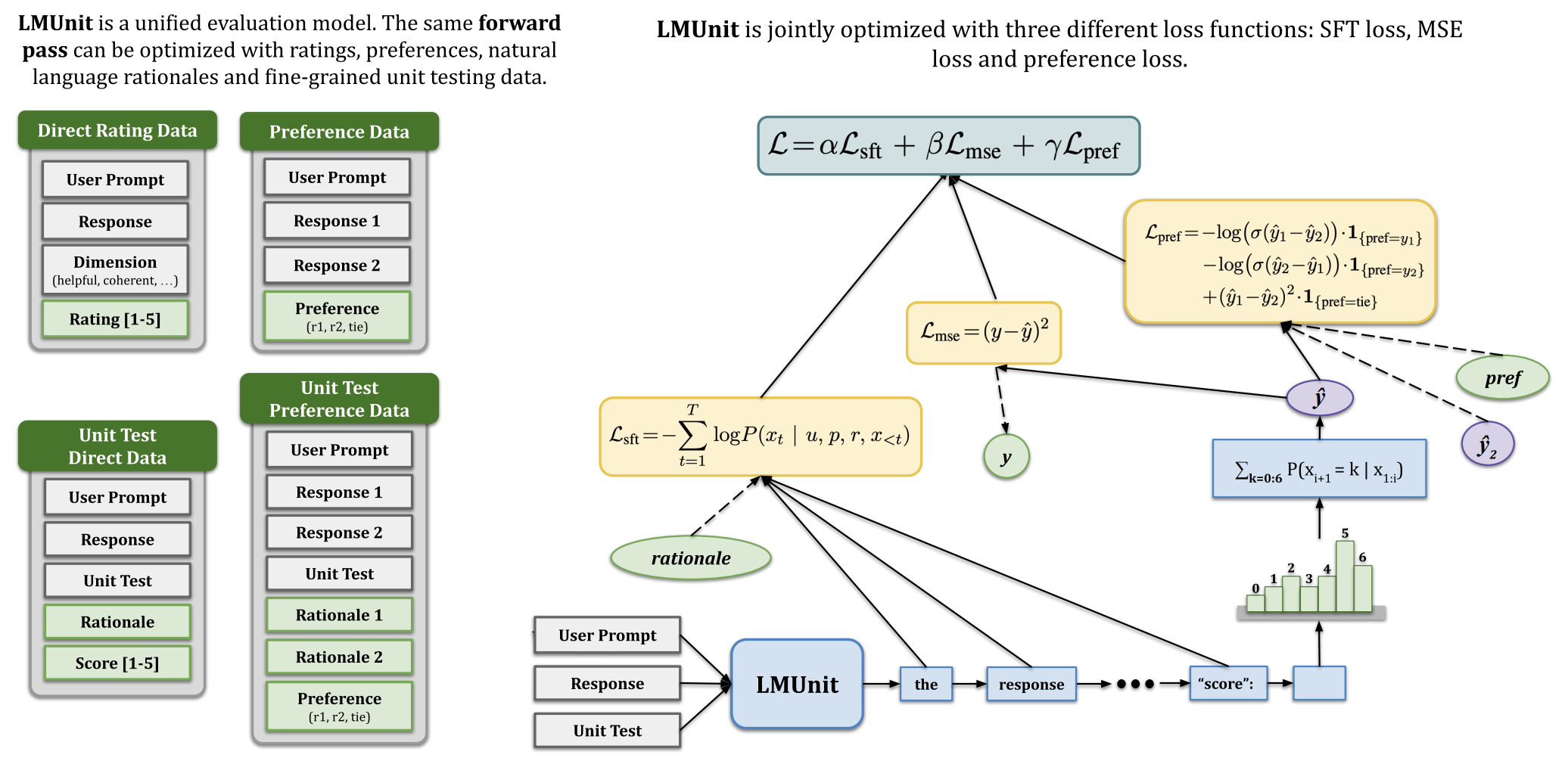
As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge – human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
BibTeX
@misc{saadfalcon2024lmunitfinegrainedevaluationnatural,
title={LMUnit: Fine-grained Evaluation with Natural Language Unit Tests},
author={Jon Saad-Falcon and Rajan Vivek and William Berrios and Nandita Shankar Naik and Matija Franklin and Bertie Vidgen and Amanpreet Singh and Douwe Kiela and Shikib Mehri},
year={2024},
eprint={2412.13091},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2409.15254}
}