Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
Abstract
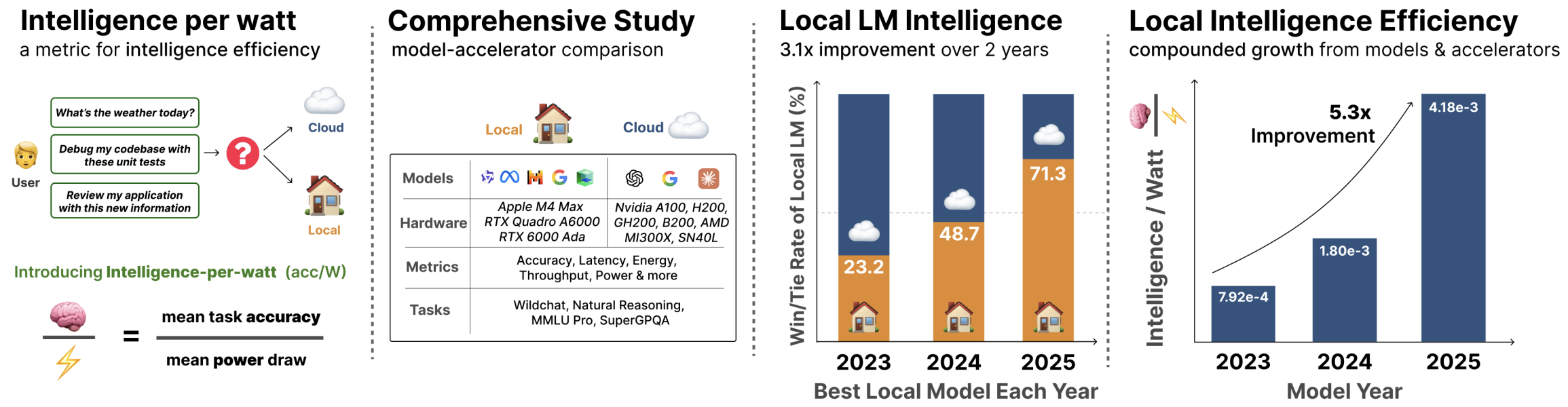
Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (≤20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals three findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking progress.
Coverage & Adoption
Selected industry, analyst, and community references to Intelligence per Watt as a metric for AI efficiency.
Industry & Analyst
-
Slingshots // Two: Our Second Grant CohortLaude Institute · Feb. 2026
-
How AI Will Reshape Computer Systems by 2035: A Jeffersonian Dinner in San Francisco about Our 10,000x FutureComputing Research Association (CRA) · Apr. 2026
-
Scaling Token Factory Revenue and AI Efficiency by Maximizing Performance per WattNVIDIA Developer Blog · Mar. 2026
-
Microsoft's Maia 200 Rewrites the Rules of Agent Intelligence per WattGartner · 2026
-
Small Models, Hazy ResearchIBM Research · Nov. 2025
-
Intelligence per Joule: The New Metric for True AI Value and EfficiencySambaNova Systems · Nov. 2025
-
Measure What Matters: Intelligence per Watt & Joule (Webinar)SambaNova × Stanford · Jan. 2026
-
Intelligence Per Watt: A New Metric for AI's FutureSnorkel AI · Nov. 2025
-
EDB pitches intelligence per watt for AI data layer (IT Brief Asia)EnterpriseDB · Apr. 2026
-
Intelligence per Watt: Edge versus CloudEmbedl · 2026
Community & Social
-
Intelligence per PicojouleReiner Pope (MATX), with Clive Chan and Dylan Patel · Apr. 2026
-
Intelligence per Joule increased 18x in 16 monthsAlex Cheema (EXO Labs) · 2026
BibTeX
@misc{saadfalcon2025intelligenceperwatt,
title={Intelligence per Watt: Measuring Intelligence Efficiency of Local AI},
author={Jon Saad-Falcon and Avanika Narayan and Hakki Orhun Akengin and J. Wes Griffin and Herumb Shandilya and Adrian Gamarra Lafuente and Medhya Goel and Rebecca Joseph and Shlok Natarajan and Etash Kumar Guha and Shang Zhu and Ben Athiwaratkun and John Hennessy and Azalia Mirhoseini and Christopher Ré},
year={2025},
eprint={2511.07885},
archivePrefix={arXiv},
primaryClass={cs.DC}
}