Embedding Recycling for Language Models
Abstract
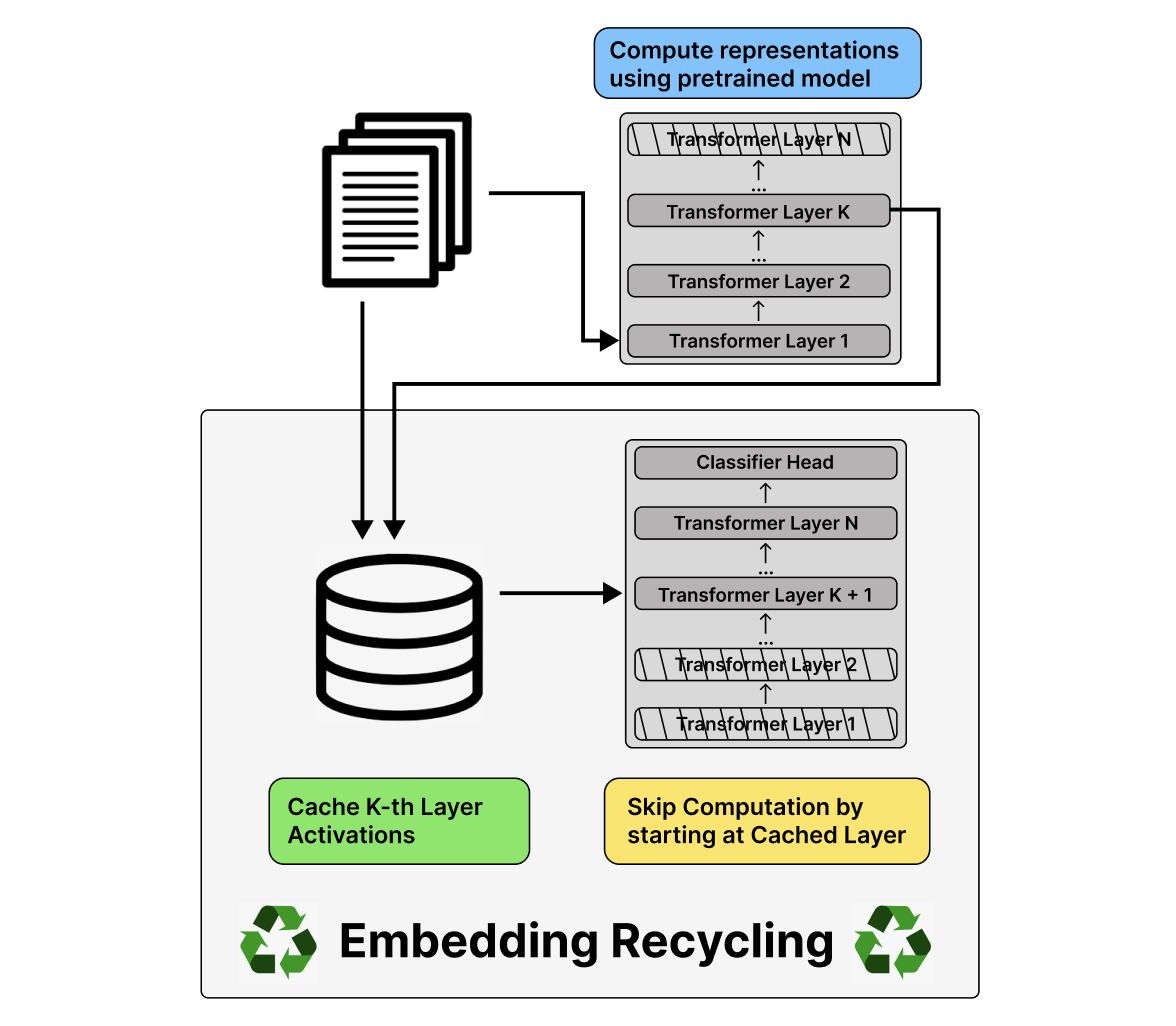
Training and inference with large neural models is expensive. However, for many application domains, while new tasks and models arise frequently, the underlying documents being modeled remain mostly unchanged. We study how to decrease computational cost in such settings through embedding recycling (ER): re-using activations from previous model runs when performing training or inference. In contrast to prior work focusing on freezing small classification heads for finetuning which often leads to notable drops in performance, we propose caching an intermediate layer’s output from a pretrained model and finetuning the remaining layers for new tasks. We show that our method provides a 100% speedup during training and a 55-86% speedup for inference, and has negligible impacts on accuracy for text classification and entity recognition tasks in the scientific domain. For general-domain question answering tasks, ER offers a similar speedup and lowers accuracy by a small amount. Finally, we identify several open challenges and future directions for ER.
BibTeX
@misc{saad2022embedding,
title={Embedding Recycling for Language Models},
author={Saad-Falcon, Jon and Singh, Amanpreet and Soldaini, Luca and D'Arcy, Mike and Cohan, Arman and Downey, Doug},
year={2022},
journal={arXiv preprint arXiv:2207.04993},
primaryClass={cs.CL}
}