UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Abstract
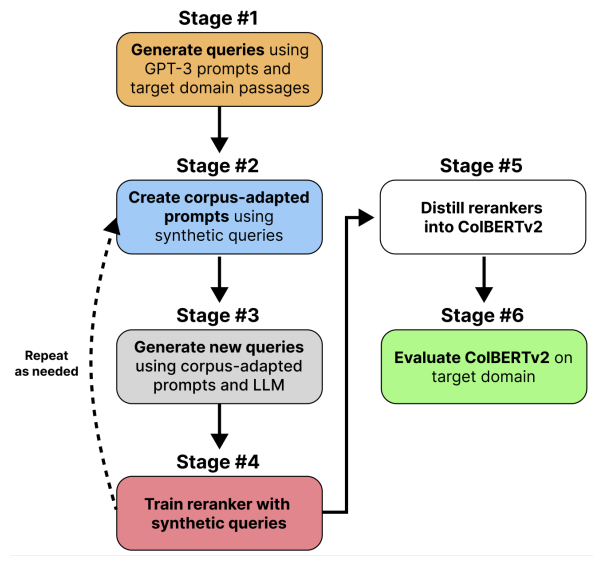
Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains and achieves substantially lower latency than standard reranking methods.
BibTeX
@misc{saadfalcon2023udapdr,
title={UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers},
author={Jon Saad-Falcon and Omar Khattab and Keshav Santhanam and Radu Florian and Martin Franz and Salim Roukos and Avirup Sil and Md Arafat Sultan and Christopher Potts},
year={2023},
eprint={2303.00807},
archivePrefix={arXiv},
primaryClass={cs.IR}
}